
فرض کنید میخواهید یک چتبات هوشمند بسازید که بتواند کارهای مختلفی را انجام دهد، مثلاً به سوالاتتان پاسخ دهد، ترجمه کند و متنهای طولانی را برای شما خلاصه کند و غیره. برای این کار اول از همه، نیاز به مدلهای بنیادی (Foundation Models) دارید که یکی از پیشرفتهترین و انقلابیترین دستاوردها در حوزه هوش مصنوعی و یادگیری ماشین به شمار میرود.
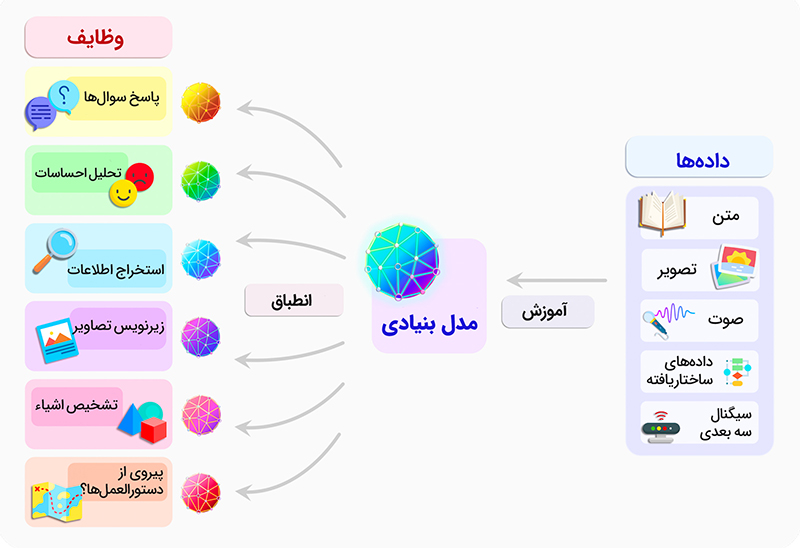
قبل از هر چیز، برای اینکه یک چت بات هوشمند با قابلیتهای متنوع توسعه داده شود، ابتدا یک مدل پایه و اساسی آموزش داده میشود تا بتواند زبان طبیعی را درک کند. به این مدل، مدل بنیادی میگویند. سپس توسعهدهندگان این مدل پایه را برای انجام کارهای خاص، مثلاً ترجمه یا پاسخ به سؤالات، تنظیم مجدد میکنند و ارتقاء میدهد که به این کار fine-tuning یا تنظیم دقیق میگویند. با این روش، دیگر نیاز نیست برای هر کار جدید، یک مدل جدید آموزش داده شود، بلکه توسعهدهندگان میتوانند از همان مدل بنیادی آموزش دیده، مدلهای تخصصیتر با کاربردهای متنوعتر بسازند.
از متن تا تصویر، مواد اولیه آموزش مدلهای بنیادی
مدلهای بنیادی با انواع مختلف و حجم بسیار بالایی از دادههای بدون برچسب (unlabeled) آموزش داده میشوند. متون و مقالات بسیار زیادی به زبانهای متنوع در منابع مختلفی مانند ویکیپدیا و غیره، تصاویر متنوع از منابعی مثل شبکههای اجتماعی، فایلهای صوتی و… از جمله این دادههای متنوع است. توسعهدهندگان از حجم عظیم و گوناگونی از دادهها استفاده میکنند تا یک مدل بنیادی بتواند الگوها و قوانین عمومی زبان و دنیای واقعی را درک کند و یاد بگیرد. پس از آموزش اولیه، این مدل بنیادی میتواند برای انجام تکالیف مختلفی مانند طبقهبندی تصاویر، تشخیص گفتار، پاسخدهی به سوالات، ترجمه متون و غیره تنظیم مجدد (fine-tuning) شود. بنابراین مدلهای بنیادی قادرند از تمامی این انواع دادهها (متن، تصویر، صوت، ویدیو و…) برای یادگیری الگوهای عمیق و کاربردی استفاده کنند.
دو نمونه برجسته از مدلهای بنیادی جهان عبارتند از مدل بنیادی GPT که توسط شرکت OpenAI توسعه داده شده و مشهورترین فاندیشن مدل دنیا است و مدل بنیادی Llama از شرکت متا. بر اساس این مدلهای پایه، محصولات متنوعی با کاربردهای گستردهای در زمینههای مختلف از جمله پردازش زبان طبیعی، ترجمه ماشینی، تولید متن، پاسخگویی به پرسشها و غیره توسعه داده شده است. امروزه با اتکا بر مدلهای بنیادی پیشآموزش دیده، میتوان محصولات و خدمات هوشمندی را به سرعت و با بهرهوری بالا توسعه داد که تا پیش از این غیرممکن بود. مدلهای بنیادی که تحولی بزرگ در حوزه یادگیری ماشین به حساب میآیند، با تغییر دیدگاه متخصصان هوش مصنوعی در مورد اینکه باید چگونه مدلها را آموزش داد، فرصتهای بسیار ارزشمندی را در زمینههای مختلف فراهم میآورند، در ادامه همراه ما باشید تا به مهمترین این فرصتها اشاره کنیم.
فرصتهای مدلهای بنیادی
مدلهای بنیادی در حوزه هوش مصنوعی، افقهای جدیدی را برای نوآوری و توسعه سریع محصولات و خدمات مبتنی بر AI گشوده است. این مدلها با قابلیت یادگیری انواع دادههای متنی، تصویری، صوتی و غیره و پردازش آنها، زمینه را برای خلق راهحلهای نوآورانه در بسیاری از حوزههای صنعتی و تجاری فراهم میکنند. بهرهگیری از مدلهای پیشآموزش دیده نه تنها روند توسعه محصولات AI را تسریع میبخشد، بلکه با کاهش نیاز به آموزش کامل یک مدل جدید، صرفهجویی قابل توجهی در هزینهها به همراه خواهد داشت. این امر، فناوری هوش مصنوعی را برای طیف گستردهتری از توسعهدهندگان و شرکتها در دسترس قرار میدهد. در ادامه همراه ما باشید تا به صورت جزئیتر به فرصتهایی که مدلهای بنیادی در اختیارمان قرار میدهند، بپردازیم.
تسریع در توسعه محصولات AI
همانطور که گفتیم با بهرهگیری از مدلهای پیشآموزش دیده، میتوان محصولات AI متنوعتر و کارآمدتری ساخت. از آنجایی که فاندیشن مدلها بستری غنی برای ساخت محصولات هوش مصنوعی هستند، توسعهدهندگان و محققان به جای اینکه از ابتدا شروع کنند میتوانند بر روی مدلهای از قبل آموزش داده شده کار کنند. این رویکرد علاوه بر تسریع بخشیدن به فرایند توسعه، فناوری هوش مصنوعی را نیز در دسترستر میکند، زیرا که ویرایش و تنظیم مجدد مدل بنیادی موجود نسبت به آموزش یک فاندیشن مدل جدید به منابع محاسباتی و تخصص کمتری نیاز دارد. با تنظیم مجدد، مدلهای بنیادی تواناییهای مختلفی را کسب میکنند و به محصولات کارآمدتر و کاربردیتری تبدیل میشوند و این یکی از روشنترین فرصتهایی است که فاندیشن مدلها برای توسعه تکنولوژی ایجاد میکنند.

صرفهجویی در هزینهها با مدلهای بنیادی
برای آموزش یک مدل بنیادی به نیروی متخصص و زمان نسبتا زیادی نیاز است. علاوه بر این توسعه مدلهای بنیادی به دلیل فراهم کردن سختافزار، دادهها و نیروی ماهر و متخصص، هزینه زیادی دارد. اما بعد از آموزش اولیه وقتی یک مدل پایه آماده شد از همان مدل میتوان برای انجام وظایف و کارهای جدید استفاده کرد و دیگر نیاز به سرمایهگذاری اضافه نیست.
از طرف دیگر، با یک بار آموزش دادن به فاندیشن مدلها یا استفاده از مدلهای بنیادی موجود، شرکتها دیگر نیازی ندارند مدلهای پایه جدیدی را از ابتدا آموزش دهند تا محصولات کاربردی و متنوعی را بر اساس آن بسازند. بلکه میتوانند از مدلهای پایه آماده و پیشآموزش دیده استفاده کنند. این موضوع باعث کاهش قابل توجه هزینهها برای شرکتهایی میشود که بر هوش مصنوعی مولد تمرکز دارند.
بگذارید این را با یک مثال توضیح دهیم. فرض کنید یک شرکت میخواهد یک مدل هوش مصنوعی برای تشخیص تصاویر پزشکی آموزش دهد. برای این کار باید دادههای آموزشی نظیر تصاویر پزشکی را جمعآوری کند و مدل را با آنها آموزش دهد. این کار میتواند هزینه بسیار بالایی داشته باشد ولی بعد از اتمام موفقیتآمیز آموزش، مدل بنیادی آماده است و حالا میتوان از این فاندیشن مدل، برای کاربردها و وظایف دیگری نظیر تشخیص سرطان پوست و بیماریهای چشمی استفاده کرد. برای اضافه کردن این کاربردهای جدید به مدل بنیادی موجود، نیاز نیست که مدل را دوباره از نو آموزش دهیم، همچنین آموزشهای تخصصی آن هزینه بسیار کمتری دارد زیرا که مدل پایه از قبل آموزش دیده و تا حدی برای یادگیری تخصصی آماده است.
امکانات بالقوه مدلهای بنیادی در صنعت و تجارت
مدلهای بنیادی قابلیت پردازش انواع مختلف دادهها مانند متن، تصویر، ویدیو و صوت را دارند. این ویژگی چندحالتی باعث میشود آنها بتوانند در حوزههای متنوعی مانند پردازش زبان طبیعی، بینایی ماشین، رباتیک و غیره به کار گرفته شوند. علاوه بر این، قابلیتهای تولیدی و استدلالی قوی مدلهای بنیادی، آنها را به ابزاری توانمند برای حل مسائل پیچیده به ویژه در حوزههایی مانند اثبات قضایای ریاضی تبدیل کرده است.
مدلهای بنیادی با توانایی درک و تولید زبان طبیعی، میتوانند در حوزههای متنوعی از جمله پردازش زبان طبیعی، ترجمه ماشینی، تولید محتوا، پاسخگویی به پرسشها، خلاصهنویسی، چت باتها و غیره کاربرد داشته باشند. این گستردگی کاربردها، فرصتهای تجاری و تحقیقاتی بسیاری را ایجاد میکند.
اتوماسیون فرایندهای کسبوکار با مدلهای بنیادی
محصولاتی که بر اساس مدلهای بنیادی ساخته میشوند، میتوانند کارهای مختلفی مانند طبقهبندی اسناد، پاسخگویی به سوالات رایج مشتریان، ترجمه متون و غیره را به صورت خودکار انجام دهند و همین باعث صرفهجویی در وقت و هزینه و افزایش بهرهوری شرکتهای مختلف میشود. علاوه بر این، وقتی کارهای تکراری به مدلهای بنیادی واگذار میشود، کارمندان شرکتها و سازمانهای گوناگون میتوانند وقت بیشتری را صرف فعالیتهای خلاقانه و نوآورانه کنند. همچنین محصولات ساخته شده بر اساس مدلهای بنیادی میتواند با پاسخگویی سریع و دقیق به سوالات و نیازهای مشتریان، رضایت آنها را افزایش دهد و تجربه کاربری بهتری را فراهم کنند. همه این موارد باعث میشود فرصتهای زیادی برای افزایش بهرهوری و نوآوری در کسبوکارها ایجاد شود.
چالشهای مدلهای بنیادی
علیرغم فرصتهای بینظیری که مدلهای بنیادی در دنیای کار و شغل و تحقیقاتی علمی فراهم میکنند، توسعه این مدلهای با چالشهای جدی و قابل تاملی روبهروست. مهمترین چالشهای برای توسعه یک مدل زبانی به دادههای مورد استفاده و سختافزارهای مورد نیاز مربوط میشود. در ادامه همراه ما باشید تا دقیقتر چالشهای بنیادی را بررسی کنیم.

کمبود داده چالش اساسی در راه توسعه مدلهای بنیادی
برای توسعه فاندیشن مدلها به حجم بسیار زیادی از دادههای متنوع نیاز است. مثلا برای آموزش یک مدل بنیادی جهت پردازش زبان طبیعی، حداقل چندین میلیون کلمه متن لازم داریم وجمعآوری این حجم از داده بسیار دشوار و وقتگیر است. علاوه بر این، ممکن است مسائل حریم خصوصی، مالکیت معنوی و یا مشکلات برچسب زدن دادهها وجود داشته باشد. همچنین اطمینان از کیفیت و نمایندگی دادهها نیز از گامهای اولیه و اساسی آموزش فاندیشن مدلهاست. علاوه بر همه اینها دادهها باید کیفیت بالایی داشته باشند و نماینده مناسبی برای دنیای واقعی باشند تا سوگیری نداشته باشند و تعمیمپذیری مدل بهتر باشد. در نهایت، جمعآوری، تمیزکاری و سازماندهی حجم بالایی از دادهها نیازمند منابع و تخصص زیادی است که میتواند از مهمترین چالشهای مدلهای زبانی باشد.
اهمیت کیفیت و نمایندگی دادهها در کاهش سوگیری مدلهای بنیادی
بعد از پیدا کردن حجم قابل قبولی از انواع دادهها، تنوع آنها نیز اهمیت دارد. زیرا که سوگیری یادگیری ماشینی یکی از چالشهای مهم در حوزه هوش مصنوعی و یادگیری ماشین است.
سوگیری زمانی رخ میدهد که دادههای آموزشی به گونهای نامتوازن یا ناکافی باشند که منجر به ایجاد الگوها یا قوانین غلط در مدلهای یادگیری ماشین میشود. به عنوان مثال، اگر دادههای آموزشی ما عمدتاً شامل تصاویر و اطلاعات افراد سفیدپوست باشد، ممکن است مدل بنیادی ما در ارزیابی و تحلیل دچار تعصبات نژادپرستانه شود. بنابراین برای مقابله با سوگیریهای قومیتی، اخلاقی و غیره راهکارهای مختلفی وجود دارد، راهکارهایی نظیر بررسی دقیق دادههای آموزشی برای یافتن الگوهای نادرست احتمالی، افزایش تنوع و توازن در دادههای آموزشی (مثلاً از نظر جنسیت، نژاد، سن و …)، ارزیابی مداوم عملکرد مدل بر روی دادههای متنوع و شناسایی سوگیریهای احتمالی، استفاده از تکنیکهای خاص برای کاهش سوگیری مثل بازنمونهبرداری دادهها و در نظر گرفتن ملاحظات اخلاقی و اجتماعی در تمام مراحل طراحی و اجرای مدلهای یادگیری ماشین.
به طور کلی، شناسایی و مدیریت سوگیریها نیازمند توجه جدی به جنبههای اخلاقی در تمامی مراحل توسعه مدلهای هوش مصنوعی است.
چالش تفسیرپذیری مدلهای بنیادی
مدلهای پایه گاهی اوقات تصمیمات و استدلالهایی را ارائه میدهند که برای انسان قابل درک نیست. مثلاً در تشخیص بیماری، ممکن است یک مدل، یک بیماری خاص را تشخیص دهد، اما دلایل این تصمیم برای ما شفاف نباشد. این عدم شفافیت میتواند نگرانیهایی در مورد اعتماد ما به چنین مدلهایی ایجاد کند. بنابراین، تفسیرپذیری یا قابلیت درک دلایل تصمیمگیری مدلهای پایه، یکی از چالشهای مهم در این حوزه محسوب میشود. البته که تلاشهای زیادی برای بهبود تفسیرپذیری این مدلها در جریان است، زیرا درک نحوه استدلال و تصمیمگیری آنها برای افزایش اعتماد و پذیریش این سیستمها در کاربردهای مختلف ضروری است.
تفسیرپذیری به ما امکان میدهد تا مکانیزمهای پشت پرده مدلها را بهتر درک کنیم و از آن برای اصلاح، بهینهسازی و توسعه بیشتر آنها استفاده کنیم. همچنین میتواند به شناسایی خطاها و مشکلات احتمالی در این سیستمها کمک کند.
هزینههای سرسامآور سختافزاری در آموزش مدلهای بنیادی
مدلهای بنیادی بزرگ مقیاس مانند GPT که میلیاردها پارامتر دارند، نیازمند منابع محاسباتی بسیار زیادی برای آموزش هستند. آموزش این مدلها میتواند چندین کارت گرافیکی پیشرفته و ماهها زمان نیاز داشته باشد. این امر منجر به هزینههای سرسامآور سختافزاری و مصرف انرژی زیاد در حین آموزش میشود. علاوه بر این، پس از آموزش هم استقرار و بهرهبرداری کارآمد از این مدلهای عظیم در محیطهای واقعی کار آسانی نیست و نیازمند زیرساختهای نرمافزاری و سختافزاری پیشرفته است.
آینده روشن فاندیشن مدلها با وجود چالشهای اجتنابناپذیر
علیرغم همه این چالشها آینده مدلهای بنیادی در هوش مصنوعی بسیار امیدوارکننده به نظر میرسد. انتظار میرود به مرور زمان این مدلها عملکرد بهتری در انجام وظایف متنوع داشته باشند و بتوانند محتوای چندرسانهای را بهتر درک کنند. البته که باید مسائلی مانند نیاز به تدوین قوانین و استانداردهای نظارتی برای تضمین ایمنی و اخلاقی بودن این فناوری و جلوگیری از سوگیری دادهها را جدی گرفت تا از آسیب احتمالی این مدلها در برخی مشاغل و صنایع جلوگیری کرد.